
Recently, I attended various sessions at QCon London 2025, and one that I liked in particular was Sam Newman´s session on Timeouts, Retries, and Idempotency in Distributed Systems. My InfoQ colleague Olimpu Pop wrote an excellent news item on InfoQ, yet I wanted to write a more in-depth blog post on the session. I also feel that this topic relates to integration and building cloud solutions.
Hence, this post discusses his session, which tackles the often overlooked but critical dimensions of distributed systems: timeouts, retries, and idempotency. Delivered with clarity and urgency, it provides a blueprint for designing systems prioritizing resilience without sacrificing performance.
While much attention in modern software architecture is paid to scalability, service meshes, and observability, this post challenges that focus by spotlighting what can quietly and catastrophically derail a system—poor handling of network failures and repeated operations.
Timeouts: The Silent Guardians of System Health
Timeouts were introduced as a performance lever and a protective mechanism. A timeout isn’t about rushing a request; it’s about setting boundaries. It enforces a contract that prevents one unresponsive component from exhausting the system’s resources.
The guiding philosophy was profound yet straightforward: timeouts prioritize the overall system’s health over the success of a single request. Letting a request fail fast, while seemingly harsh, is an act of system-wide preservation.

(Source: Sam Newman’s Definition of Insanity Slide Deck)
Newman has explored scenarios in which a frontend service invokes multiple backend APIs. Without timeouts, a stalled backend can tie up resources indefinitely, leading to cascading failures. The takeaway was that timeout values should be explicitly defined and never left to defaults.
Strategic Retries: When Retrying Becomes a Threat
When misused, retries were described as potential self-inflicted denial-of-service attacks. Sam Newman´s discussions on retries highlighted how indiscriminate retrying, especially under load, can amplify outages and destabilize services.
Instead, Newman recommends adopting structured retry strategies using exponential backoff, jitter, and bounded attempts. These techniques reduce the likelihood of synchronized retry storms and give struggling services a chance to recover.
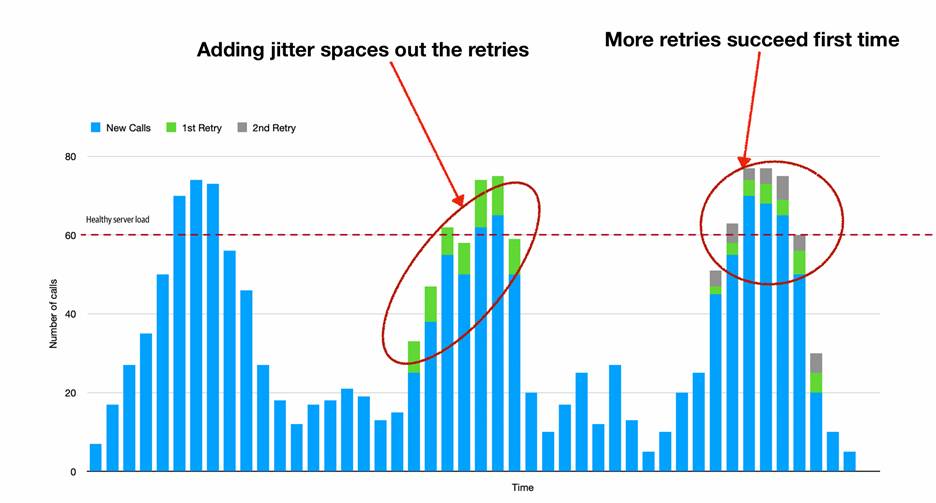
(Source: Sam Newman’s Definition of Insanity Slide Deck)
Libraries like Resilience4J and Polly were noted for their configurable retry mechanisms, but attendees were cautioned that no tool can replace intentional system design. The message was clear: retries should be deliberate, context-aware, and failure-conscious.
Idempotency: Making Repetition Safe
Newman then turned to idempotency—the idea that repeating an operation should have the same effect as doing it once. In distributed environments, duplicate requests are inevitable, whether due to retries (as discussed earlier), client behavior, or network glitches.
Without idempotent operations, these duplicates can lead to data corruption, financial discrepancies, or compounding business logic errors. Imagine, for example, a scenario where a payment request is processed multiple times due to network issues.

(Source: Sam Newman’s Definition of Insanity Slide Deck)
A practical solution discussed was using idempotency keys—unique identifiers that allow systems to recognize and ignore repeated operations. This approach was framed as essential, not optional, for write operations. However, achieving idempotency, especially in complex distributed systems, isn’t always straightforward. For example, ensuring idempotency across multiple services or databases (a distributed transaction) can be particularly challenging, requiring careful coordination and potentially distributed locking mechanisms. Even with idempotency keys, issues like key generation, storage, and handling concurrent requests must be addressed thoughtfully.
Participants were encouraged to audit their systems using the following question: Can this operation be safely retried? If not, safeguards need to be built in.
Timeout Budgets: Coordinating Time Across Services
One of the more advanced concepts introduced was timeout budget propagation. Rather than treating timeouts in isolation, systems should treat them as shared contracts across the entire call chain.
For instance, if a user’s request has a 2-second budget, every downstream call should be completed within its portion of that total time. Once the budget is exhausted, subsequent calls should short-circuit to avoid waste.
This leads to more intelligent and responsive systems that avoid making pointless calls and fail quickly with clarity.
Tools Are Helpers, Not Saviors
The final theme reinforced the importance of understanding over automation. Tools like Resilience4J and Polly provide robust functionality but cannot replace deep knowledge of a system’s behavior under duress.
It was emphasized that installing these libraries without understanding failure patterns, latency curves, and operational context could worsen reliability.
The recommendation was for teams to invest time in studying their systems’ behavior, conduct chaos testing, and build observability around failure and recovery mechanisms.
Bringing It Together: A Blueprint for Resilience
The trio of timeouts, retries, and idempotency formed a comprehensive framework for resilience. They were positioned not as technical trivia but as strategic imperatives.
Attendees were encouraged to formalize resilience patterns, create shared documentation for timeout policies, and continuously test their assumptions through simulated failures.
The session closed by highlighting that resilience does not emerge by accident. It must be engineered deliberately and iterated constantly.
Conclusion: From Fragile to Fault-Tolerant
Newman´s talk offered actionable insights and cautionary tales for software teams building and operating distributed systems. It shifted the conversation from high-level abstraction to the gritty realities of how distributed systems behave under failure.
In a landscape increasingly dominated by complexity and scale, small design choices—timeout values, retry conditions, and idempotency guarantees—determine whether systems bend or break.
The overarching message was simple: Every system fails. The only question is how gracefully it does so.
Key Takeaways of the session:
- Timeouts Are About System Health, Not Just Performance: Timeouts protect the entire system by ensuring a single failing component doesn’t compromise the larger architecture.
- Retries Need Strategy, Not Hope: Blindly retrying failed requests can worsen problems. Controlled, contextual retries with backoff policies are essential.
- Idempotency is a Survival Mechanism: Distributed systems must gracefully handle repeated operations without unintended side effects.
- Timeout Budgets Should Be Propagated: Passing timeout constraints downstream ensures coordinated request handling and better system responsiveness.
- Tools Matter, But Understanding Comes First: Resilience4J, Polly, and similar libraries are powerful, but they must be used with a solid grasp of distributed system behavior.
Lastly, his website page provides more information on his topic and details on his book about distributed systems.
